1960년대 퍼셉트론을 쌓아가기 시작하는데 이때 최초의 멀티 layer 퍼셉트론 network가 되지만 hardware였습니다. 이때 가중치들 즉 어떤 파라미터의 approach를 도입한 것만으로도 큰 도약으로 보이며 이에 대한 기대가 매우 컸습니다.
하지만 이후 컴퓨터의 성능 등의 문제로 효과는 미치지 못했으며 80년대 중반까지는 신경망의 암흑기라 불리는 침체기로 접어들게 되었습니다.
이후 1986년에 제프리 힌턴 교수님 등 공저자가 포함된 back-propagation을 도입하며 이는 미분이 가능하며 가중치를 체계적인 방법으로 찾아갈 수 있다는 것을 의미합니다.
2006년 경 각 단계 RBM을 이요해서 학습 시키고 계속하고 학습시키면서 각각 선행학습을 시킨 다음에 이들을 큰 덩어리로 묶어서 back-propagation을 돌려서 이후 파인튜닝을 하는 방식이 제대로 동작하면서 최초로 2006년에 제대로 동작하는 것을 성공시킵니다.
Activation Function
시그모이드 함수는 0과 1사이의 확률과 같이 나오기 때문이 들어오는 입력값에 대해 가중치 영향력을 주기에 적합합니다. 하지만 더이상 사용하지 않을 만한 문제점이 있습니다.
- 뉴런이 포화되어서 gradients를 없앨 수 있다.

x가 크면 기울기가 0이 나오게 되는데요. 작을 때도 0이 나오기 때문에 gradient가 없어지는 즉 back propagation이 멈추는 결과를 나오게 됩니다.
그래서 이 그래프의 가운데지점을 active region of sigmoid라고 부르며 왼쪽 끝, 오른쪽 끝부분을 saturated regime 즉 포화지점이라고 표현을 하게 됩니다.
- saturated neurons "kill" the gradients
- sigmoid의 결과는 zero centered가 아니다.
tanh(x)

x의 값이 작거나 큰 경우 saturated가 발생할 수 있습니다. [-1,1]
ReLU

현재 activation Functions의 디폴트 Value입니다. max(0,x)이며 양수인 값에서는 saturated가 발생하지 않으며 앞선 두개의 functions들 보다 6배 빠릅니다.
하지만 이것도 문제점을 가지는데 0이상의 값을 가지기에 zero-centered가 아닙니다. 그리고 0보다 작을 때 gradient를 어떻게 해야 하는지에 대한 의문이 존재합니다.
dead ReLU가 발생할 때 BIAS를 0으로 초기화하는 것이 많은데 dead ReLU를 방지하기 위해 0.01 같은 작은 값으로 하는 방법도 있지만 이것은 찬반이 갈립니다.
Leaky ReLU
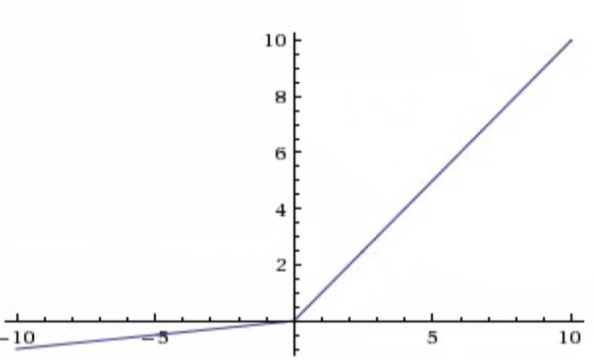
x가 0보다 작은 곳에서 기울기가 0이 아닌 조금 작은 값을 가지는 것을 볼 수 있습니다. saturated가 발생하지 않으며 그렇기 때문에 gradiant가 죽는 경우가 발생하지 않는 것입니다. 이는 ReLU보다 낫다는 분들도 있지만 완전히 검증이 끝난 것은 아니기에 감안을 하고 사용하면 됩니다.
PRelu
f(x) = max(ax, x)
알파가 0이라면 Relu와 동일하면 0.01x면 Leaky ReLU와 동일한거겠죠?

Exponential Linear Units(ELU)
X가 0이상인 경우는 형태가 같은데 ELU는 둥글게 나타나게 됩니다. 하지만 계산하는데 무리가 갈 수 있다는 단점이 있습니다.
특별한 경우가 아니면 ReLU 그리고 특별히 시도할 경우가 있는 경우 Leaky ReLU/ Maxout / PRelu 등을 사용하면 됩니다.
가중치 초기화
모든 가중치가 0으로 초기화되면 모든 뉴런들이 동일한 연산을 수행하게 됩니다.
가중치를 초기화하는 기본적인 아이디어는 작은 Random number를 사용하는 겁니다. 가우시안 표준분포
W = 0.01* np.random.randn(D, H)
식으로 하면 됩니다. 하지만 이 경우 데이터가 커질 때 문제가 발생하는데요.
Batch Normalization
relu를 적용하거나 가중치 초기화를 신중하게 하는 방법으로 해결하다가 Batch Normalization은 학습의 전반 과정을 안정화 시키도록 근본적인 방법을 제시한 방안입니다.
기본적으로 학습을 하는데 있어서 발생하는 불안정화는 내부적으로 입력값의 분포가 달라지기 때문에 이런 것이 발생한다고 보고 각 레이어를 지나갈 때 마다 Normalization을 하더라도 미분 가능한 함수이고 이걸 적용하면 된다는 것입니다.
Hyperparameter Optimazion
Cross-validation strategy
반복을 너무 여러번 하지 않습니다. 에폭을 조금만 반복하고 감을 잡으면 두번째 단계에서 러닝타임을 길게 해주고 세부적으로 search를 시작하는 것입니다.
최적값을 찾아야 하는 하이퍼파라미터는 여러개 존재하는데 각 노드는 몇개를 할 것인지 러닝 rate의 decay schedule은 어떻게 잡고 update type, regularization은 l2로 할 것인가 dropout을 할 것인가 믹싱을 하듯이 튜닝을 해야 한다는 것입니다.
'IT 프로그래밍 > AI' 카테고리의 다른 글
| [cs231n] Localization - as Regression (5) | 2024.11.15 |
|---|---|
| [cs231n] CNN (1) | 2024.11.15 |
| [cs231n] 3강 Neural Network NN (0) | 2024.11.08 |
| [cs231n] 2강 Classification Pipeline (0) | 2024.11.07 |
| [컴퓨터네트워크] part2-4 FTP (0) | 2024.10.06 |