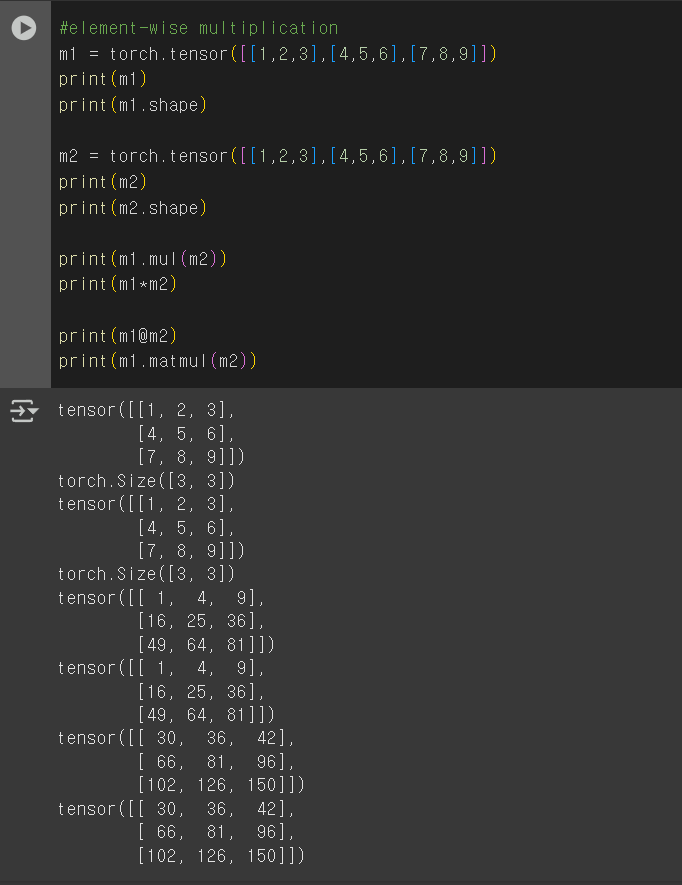
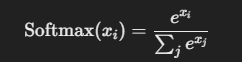벡터가 선형변환이 되고 있는 것 weight를 곱하는 것은 곧 선형변환입니다. 벡터를 가만두지 않고 이동시키는 것 선형적인 변환을 통해 이동하는 것이 선형변환이고 어디다가 놓을지를 학습시키는 것입니다. n번째 시점에서 어떤 단어를 볼지 보고서 weighted sum 그 vector를 context vector로 삼고 y햇을 뽑아서 softmax를 하는 것이 바로 seq-to-seq입니다. 기존에는 C1=C2=C3=C4같이 H3로 쓴 것입니다. 하지만 불균형적으로 담겨있습니다. 어떤 단어를 많이 담는지는 모릅니다. 그건 ai가 하는 것입니다. RNN -> RNN + attention -> Transformer RNN+ attention의 문제점멀수록 잊혀집니다. 그리고 갈수록 흐려지는 정보에 at..