Augmentation (증강)
CNN에는 이미지와 label이 존재합니다. 이것으로 오차를 줄여나가는 방법으로 분류를 합니다.
데이터 증강에서는 원본의 이미지를 어떤 식으로든 변형하는 과정 하나가 추가가 됩니다. 어떠한 변형 방법을 이용할 것인지는 다양한 증강 방법이라고 볼 수 있습니다.
데이터 증강은
- 레이블은 변함이 없고 픽셀의 내용을 바꿈
- 변경된 데이터로 학습을 함
- 매우 폭넓게 이용이 됨
1. Horizontal flips
이미지를 거울에서처럼 반대로 만들어주는 것으로 mirror image라는 표현도 합니다.
2. Random crops/scales
이미지를 랜덤하게 잘라주고 스케일도 다양하게 해줍니다. 랜덤하게 잘라내고 크기를 가지는 것을 학습을 시키는 것입니다.
- 이미지 랜덤 선택 [256, 480]
- 트레이닝 이미지 크기 조정
- 샘플 랜덤 224 X 224 Patch
이미지 전체가 아닌 crop에 대한 학습이 이루어지기에 테스트에도 정해진 crop을 통해서 이를 평균하는 작업을 test 때 하게 되는 것입니다.
ResNet
- 이미지 사이즈 조정을 5가지 스케일로 조정
- 각각을 224x224 crop을 10개 사용
3. color jitter
이미지의 색상 속성을 랜덤하게 변형하여 모델이 다양한 조명 조건, 색상 변화에 대해 강건해지도록 만드는 기술
1. Apply PCA to all [R, G, B] pixels in the training set
- PCA(Principal Component Analysis)를 사용하여 훈련 세트의 모든 픽셀(R, G, B 채널)을 분석
- PCA는 픽셀 값의 주성분(Principal Components)을 계산하여 RGB 채널의 상관 관계를 파악
- RGB 값은 서로 상관관계가 높기 때문에, PCA를 통해 데이터의 주요 방향(Principal Component)을 찾음
2. Sample a "color offset" along principal component directions
- 주성분 방향(Principal Component)에서 임의의 색상 오프셋(Color Offset) 값을 샘플링
- 각 주성분 방향에 따라 이미지 색상 정보를 변형시킬 값을 생성
- 이 값은 색상에 랜덤성을 부여하여 데이터 증강을 수행
3. Add offset to all pixels of a training image
- 앞서 생성된 색상 오프셋 값을 훈련 이미지의 모든 픽셀에 추가
- 예를 들어, 특정 주성분에서 빨간색(R) 성분을 더 강조하거나 감소시키는 방향으로 색상을 변경
- 이렇게 하면 이미지의 전반적인 색감이 약간 변화하면서도 기존의 구조적 정보는 유지
핵심 아이디어
이 과정은 이미지를 약간 변형하여 모델이 다양한 조명 조건이나 색상 변화에 대해 강건하도록 만듭니다. 특히, PCA를 사용해 RGB 채널 간의 상관 관계를 분석하고, 이에 따라 색상 변화를 자연스럽게 만드는 것이 핵심입니다.
데이터셋에 어떠한 invariance가 필요한지 잘 파악한다음 창의적인 것을 적용할 수 있을 것입니다.
일반적 관점
1.traning : add random noise
2. test : marginalize over the noise
데이터 증강은 학습 과정에서 랜덤 노이즈를 추가하는 방식으로 볼 수 있습니다. 이와 유사한 효과는 Batch Normalization이나 모델 앙상블에서도 얻을 수 있습니다.
데이터 증강은 구현이 매우 간단하며, 특히 데이터셋이 작은 경우에 효과적입니다. 학습 시에는 노이즈를 추가하여 모델의 일반화 성능을 높이고, 테스트 시에는 데이터를 평균화(Averaging)하여 안정적인 예측을 제공합니다.
과연 데이터가 많이 필요한가? CNN 기준
미리 학습된 모델 사용
이미지넷에서 학습을 할 때는 미리 학습된 모델을 다운로드 받아서 사용할 수도 있고, 직접 학습을 진행할 수도 있습니다. 일반적으로 미리 학습된 모델을 사용하는 것이 더 효율적입니다.
데이터셋이 작은 경우의 학습 전략
하지만 데이터셋이 작을 경우, FC-1000과 Softmax 레이어만 학습하고 나머지 부분은 Freeze(고정) 시킵니다. 즉, 파라미터는 변경되지 않으며, 이미지넷에서 이미 학습된 부분들은 특성 추출기(feature extractor) 역할을 하게 됩니다. 우리의 데이터는 FC-100과 Softmax에 대해서만 학습을 진행하며, 다른 부분은 Freeze 되어 있으므로 체크포인트처럼 저장됩니다. 이때 학습이 진행되는 부분은 메모리에 올라와서 동작합니다.
fine-tuning을 통한 모델 조정
만약 데이터셋의 크기가 너무 크지 않거나 너무 작은 경우가 아니라면, fine-tuning을 통해 모델을 세밀하게 조정할 수 있습니다.
데이터셋 크기에 따른 학습 선택
데이터셋이 매우 크다면, 그 자체로 학습을 시킬 수 있고, 데이터가 부족하다면 FC-100과 Softmax만 학습하거나, 데이터를 조금 더 확보한 후 Freeze된 부분을 조정하는 방법으로 학습을 진행할 수 있습니다. 데이터의 크기에 따라 필요한 부분을 선택하여 학습을 진행할 수 있습니다.
전이 학습(Transfer Learning)과 성능 향상
전이 학습을 사용할 때, 처음에 학습한 모델보다 더 좋은 성능을 얻는 것에 대해 의문을 가질 수 있습니다. 예를 들어, 원본 이미지와 매우 유사한 이미지들만 분류하는 경우, 모델의 마지막 레이어(Fully Connected Layer, FC Layer)만 학습해도 충분한 성능을 얻을 수 있습니다. 이 경우, 모델의 특성 추출 부분은 그대로 두고, 최종 출력만 학습하는 방식이기 때문에 간단하게 좋은 결과를 얻을 수 있습니다.
하지만, 이미지가 전혀 관련이 없는 데이터일 경우, 이미지의 클래스와 전혀 관계가 없는 정보가 많기 때문에, 모델의 앞부분(즉, 특성 추출 레이어)도 학습시켜야 합니다. 이 때, 왜 관련 없는 데이터로 학습을 시켜도 성능이 향상되는지에 대해 의문을 가질 수 있습니다.
여기서 중요한 점은, conv-64와 같은 저수준(convolutional) 레이어는 이미지에서 기본적인 특징을 추출하는 데 사용된다는 것입니다. 예를 들어, 객체를 인식할 때, Conv-64 레이어는 색상, 질감, 에지(윤곽선) 등의 저수준 특징을 추출합니다. 이 저수준의 특징들은 어떤 이미지 분석을 하든지 기본적으로 유용한 정보가 됩니다. 따라서, 뒤쪽의 상위 레벨 레이어들은 더 구체적이고 복잡한 특징들을 인식하게 되며, 이 과정에서 전이 학습이 효과를 보게 됩니다.
결국 Low-level features가 다양한 이미지에서 공통적으로 유용한 정보로 작용하기 때문에, 전이 학습(Transfer Learning 을 통해 기존 모델을 재학습하면 다른 데이터셋에 대해서도 좋은 성능을 낼 수 있습니다. 이는 기본적으로 이미지 분석에서 공통적으로 사용되는 특징들이 유용하다는 점에서, 이미 학습된 모델을 다른 데이터에 적용할 때 성능이 향상되는 이유입니다.
데이터 유사성
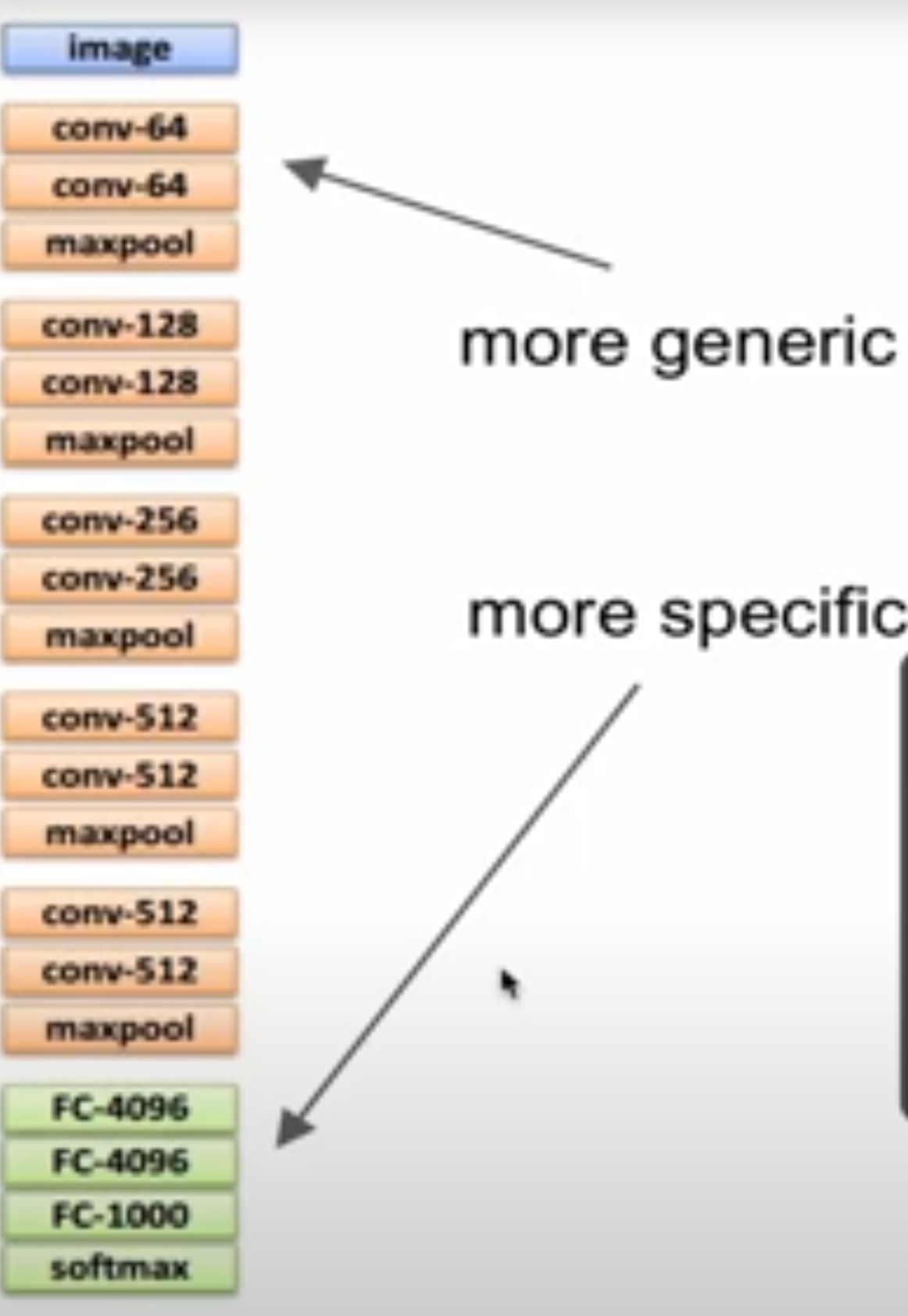
데이터의 수가 적지만 데이터의 유사성 높을 때
탑 layer에서 linear classifier로 충분
데이터의 수가 많고 데이터의 유사성 높을 때
몇 개의 데이터만 파인튜닝
데이터의 수도 적고 데이터 유사성도 작을 때
어느 부분까지 학습 시켜주고 어느 부분까지 freeze 해줄 지 상황에 따라 판단
데이터는 많지만 유사성이 적을 때
많은 데이터를 finetuning
CNN에 있어서 tranfer learning은 표준과 같이 사용해야 되는 것처럼 굳어져 있는 것이며 faster-cnn에서는 transfer learning을 사용하고 이미지 셋팅의 경우에도 conv에도 물론이고 RNN쪽에서도 Word-vector에도 transfer learning을 사용합니다.
즉 데이터가 작다면 큰 데이터를 만들거나 transfer learning을 활용하라는 것입니다. 미리 학습된 모델은 free-trained model을 모아놓은 library가 있습니다. tesnorflow나 pytorch나 이런 경우 제공을 하고 있습니다.
컨볼루션 연산 및 효과

1. Receptive Field
각 뉴런은 입력 데이터에서 특정 부분만을 보는(즉, 필터와의 컨볼루션 연산을 수행하는)데, 이 시야를 Receptive Field라고 합니다. 예를 들어, 3x3 필터는 입력 이미지에서 3x3 영역을 봅니다. 즉, 각 뉴런은 3x3 영역의 특징을 추출하게 됩니다.
2. 컨볼루션 레이어 쌓기
만약 3x3 컨볼루션을 3번 쌓는다면, 각 레이어가 이전 레이어의 출력에서 3x3 영역을 보고, 결과적으로 하나의 뉴런이 입력 이미지에서 7x7 영역을 보는 효과를 가지게 됩니다. 직관적으로 보면, 3x3 필터를 3번 쌓은 것은 7x7 필터 하나로 보는 것과 비슷한 효과를 냅니다. 즉, 여러 작은 필터들을 겹쳐서 사용하는 것이 큰 필터 하나를 사용하는 것과 동일한 표현력을 갖게 됩니다.
3. 컨볼루션 연산의 파라미터 계산
입력이 32x32x3 크기이고, 5x5 필터를 사용한다고 가정합시다. 이때 필터의 개수는 10개, stride=1, padding=2일 경우의 파라미터 계산은 다음과 같습니다:
- 입력 크기: 32x32x3
- 필터 크기: 5x5
- 필터 수: 10개
- 스트라이드: 1
- 패딩: 2
컨볼루션 연산 후 출력 크기는 32x32로, 패딩이 추가되어 입력 크기와 동일하게 유지됩니다.
파라미터 수는 각 필터에 대해 계산됩니다. 각 필터는 5x5 크기이고 입력 채널 수(3) 만큼의 값이므로, 필터의 크기는 5x5x3입니다. 여기서 +1은 바이어스(bias) 항목입니다. 따라서 하나의 필터에 대한 파라미터 수는:
(5×5×3+1)=76(5 \times 5 \times 3 + 1) = 76
필터가 10개이므로 전체 파라미터 수는:
76×10=76076 \times 10 = 760
따라서 이 컨볼루션 레이어의 전체 파라미터 수는 760개입니다.
'IT 프로그래밍 > AI' 카테고리의 다른 글
| [컴퓨터 네트워크] UDP (1) | 2024.12.03 |
|---|---|
| Gradient descent, neural networks learn (0) | 2024.11.28 |
| [cs231n] RNN, LSTM (0) | 2024.11.16 |
| [cs231n] Visualization, Adversarial examples (0) | 2024.11.15 |
| [cs231n] Localization - as Regression (5) | 2024.11.15 |