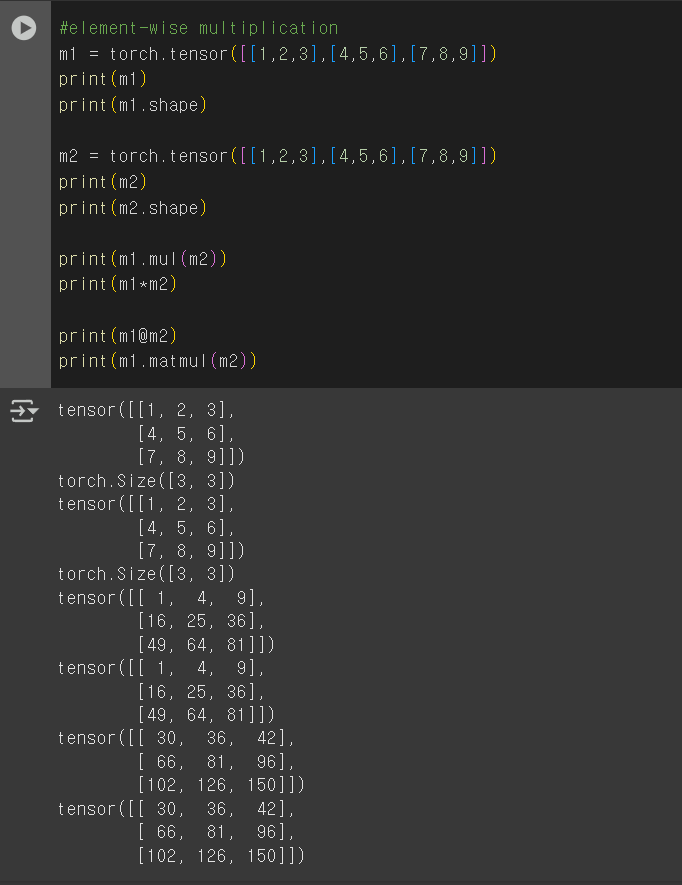
Batch Matrix Multiplication(BMM)
같은 개수의 행렬 쌍들에 대해 병렬로 행렬 곱 실행
(N,n,h)X(N,h,m) = (N,n,m)
Linear Layer
Linear Layer란?
Input과 Output을 weight로 연결하는 Layer로 각 원소들을 모두 연결하는 형태이기 때문에 Fully Connected Layer라고도 부름
Activation Function
Linear Layer의 결과를 다음 layer에 전달할 때 사용하는 함수로, 비선형 함수를 사용 sigmoid, tanh, ReLU 등이 있음
Softmax 함수
activation function으로도 쓸 수 있고 자주 사용하는 함수 중 하나입니다. 결과 classification을 할 때 output을 뽑을 때 확률 값을 출력하기 위해서 사용하는 함수입니다. 특히 Multi-Clss Classification에서 사용합니다.
기존의 확률값은 score가 음수가 되면 확률 표현을 할 수 없습니다. 만약 score가 -1이 되면 계산을 할 수 없기 때문에 그런 한계를 극복하기 위해 Softmax를 활용하며 Class가 여러 개인 경우 확률값을 출력하는 함수입니다.
각 클래스 개수가 k개일때, class별 스코어가 있을 건데 (e^2 / e^2+e^1+e^0) 입니다. 지수승을 해주면서 확률을 계산하는 것을 Softmax라고 합니다. 밑은 모든 값들을 지수승을 해주어서 시그마로 formation을 해주고 해당하는 클래스가 2개인 경우는 시그모이드와 형태가 똑같습니다.
nn.Module()
모든 뉴럴넷 모형의 기본으로 우리가 정의하는 모든 뉴럴넷 클래스는 nn.Module을 상속해야합니다. 각 layer의 함수, 신경망 구조를 정의할 때 사용합니다.
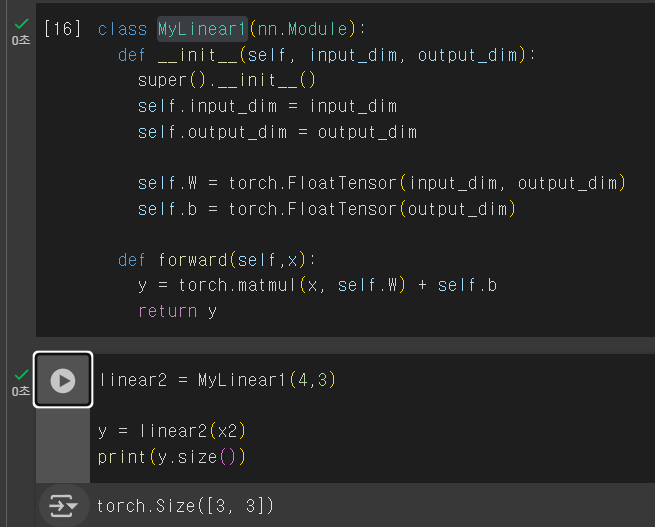
class MyLinear1(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.W = torch.FloatTensor(input_dim, output_dim)
self.b = torch.FloatTensor(output_dim)
def forward(self,x):
y = torch.matmul(x, self.W) + self.b
return y크게 neural network는 init 메서드와 forward 메서드로 구분이 됩니다. forward는 실제 input을 받아서 네트워크를 통과시키고 결과를 return하는 부분을 수행하는 것이라고 보면 됩니다. input으로 x가 들어가는 것을 볼 수 있습니다. weight matrix와 self.클래스 내부를 선언하는 Weight Matrix와 Input과 같이 한 다음에 bias를 더해주는 것을 볼 수 있습니다.
이제 선언한 클래스를 linear2로 instance를 해서 x2를 넣는 코드를 봅시다.

이전포맷
class MyLinear1(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.W = torch.FloatTensor(input_dim, output_dim)
self.b = torch.FloatTensor(output_dim)
class MyLinear2(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.W = nn.Parameter(torch.FloatTensor(input_dim, output_dim))
self.b = nn.Parameter(torch.FloatTensor(output_dim))
def forward(self,x):
y = torch.matmul(x, self.W) + self.b
return ynn.Parameter는 pytorch에게 학습이 필요한 것이라는 것을 알려주는 것입니다. Computation 그래프 안에 weight와 bias가 들어가야 한다는 것을 명시해주는 것이 nn.Parameter라고 합니다.
직접 torch.Tensor기반으로 할 때 학습시켜달라고 할 때 nn.Parameter로 감싸주어야 하는 것입니다. 지금은 그렇게 많이 쓰는 것은 아닙니다.
현재포맷
class MyLinear3(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.linear = nn.Linear(input_dim, output_dim)
def forward(self,x):
y = self.linear(x)
return y이게 현재 거의 쓰이는 포맷입니다. pytorch에는 nn.Linear를 만들면 nn.linear에서 imnput_dim, output_dim 넣으면 forward 에서 torch가 된 것을 굳이 안써도 내부 구현이 된 모듈 상에서 input으로 x를 내어주면 multiplication을 자동으로 해주기에 가져다 쓰기만 하면 됩니다.
Activation Function
torch.nn.functional : 여러가지 연산에 사용되는 유용한 함수 제공
대부분의 activation function을 제공 (relu, signoid, tanh, leeky_relu, softmax) 등
torch.nn vs torch.nn.functional : nn은 클래스, nn.fuynctional은 함수로 구현되어 있음
import torch.nn.functional as F
#sigmoid
sigmoid =nn.Sigmoid()
input = torch.randn(2,3)
print(input)
print(input.shape)
output=sigmoid(input)
print(output)tensor([[ 0.8570, 1.3529, -0.7691],
[-0.0268, -0.0862, -0.3355]])
torch.Size([2, 3])
tensor([[0.7020, 0.7946, 0.3167],
[0.4933, 0.4785, 0.4169]])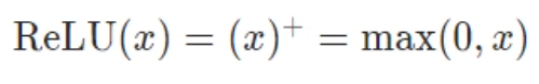
#ReLU
relu = nn.ReLU()
input = torch.randn(2,3)
print(input)
print(input.shape)
output = relu(input)
print(output)tensor([[-0.6015, -0.7388, -0.8737],
[ 0.0014, 0.7969, 0.7683]])
torch.Size([2, 3])
tensor([[0.0000, 0.0000, 0.0000],
[0.0014, 0.7969, 0.7683]]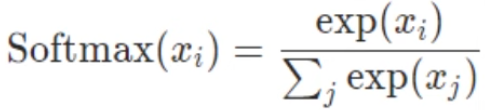
#Softmax : Dimension을 지정해주면 해당 dim의 합이 1이 되도록 지정
softmax = nn.Softmax(dim=1)
input = torch.randn(2,3)
print(input)
print(input.shape)
output = softmax(input)
print(output) #dim=1에 대해 softmax 함수 적용
output[1].sum()tensor([[ 0.9763, 1.5742, -1.2114],
[-1.6816, 1.1043, -3.1810]])
torch.Size([2, 3])
tensor([[0.3413, 0.6205, 0.0383],
[0.0573, 0.9298, 0.0128]])
tensor(1.0000)
'IT 프로그래밍 > AI' 카테고리의 다른 글
| [Loss function] MSE vs log-likelihood (0) | 2025.03.30 |
|---|---|
| [딥러닝] 기본적 개념 정리 (0) | 2025.03.24 |
| 파이토치의 구성요소 (0) | 2025.03.19 |
| 딥러닝 연구의 초점 (0) | 2025.03.18 |
| RNN이 무엇인가? 그리고 Transformer로 대체된 이유 (0) | 2025.03.17 |