지속적인 딥러닝으로 인해 이미티 Caption은 어느정도 해결이 되었습니다.
이미지를 넣고 질문을 하면 답을 해주는 것 그리고 추론하는 문제를 내줄 수 있습니다. 이제 VLM 모델들은 무쉽게 접할 수 있습니다. Llama4, Phi vision-multimodal도 있습니다. 가장 이해하기 쉬운 것은 DeppSeek-VL입니다. 도면이 무엇인지 수식까지 이해하는 걸 볼 수 있습니다.
이미지가 Input으로 들어온다면 vision encoder로 맞춰서 token으로 자르고 2048 dimension을 가진 576개의 token이 나옵니다. 이것이 LLM의 Input으로 들어가면 이미지 정보가 토큰으로 들어가고 llm을 통해 다음 텍스트 토큰을 예측합니다.
1. adapter만 트레이닝을 시킴
2. Joint VL Pre-training
3. Supervisied findtuning
visual token, text token 을 둘 다 내면서 그거에 대한 다음 토큰을 예측하는 것
비전 트랜스포머
patch + position embedding
Vit 모델은 image classification을 잘했다는 것인데 데이터를 많이 필요합니다. 해당 데이터로만 활용한 것이 아닌 매우 방대한 양으로 pretrained 한 것입니다.
Image net을 하면 cnn이 성능이 좋다가 데이터를 방대하게 넣을 때 ViT가 더 좋게 나옵니다. cnn 기반들이 성능이 좋다가 데이터 개수를 늘리니깐 CNN을 OutPerform 합니다.
ViT는 패치 단위로 자르고 이미지 패치를 1차워 벡터와 시켜서 position embedding합니다.
vit는 패치 단위로 이미지를 만들고 position embedding을 학습이 되도록 만들었는데 학습이 되는 과정중에 2d 공간 정보가 형성이 되는 것입니다.
self - attention 간의 쿼리 키 간의 관계가 있으며 여러 개의 레이어가 있고 여러 개의 어텐션이 있으며 이미지 패치 별로 score들이 나타나는데 이는 이미지와 패치간의 거리들이 되는데 이 거리를 visualization합니다.
CNN은 낮은 단계에서는 그 쿼리가 볼 수 있는 게 제한이 되어있지만 낮은 단계부터 더 작은 영역을 큰 영역을 봅니다. 토큰으로 나누고 학습 과정중에 공간 정보를 자연스럽게 배우도록 한 것
ViT (Vision Transformer)
분류로 해결하면 되지만 하지만 여러 가지 물체가 있을 때 어떻게 대답해야할지 애매해집니다. 전체 이미지의 맥락을 파악하는 경우 ViT가 잘 동작합니다.
Transformer는 언어 처리에 효과적인 성능을 가지고 있습니다.
Feature을 추출하는 인코더, 토큰을 생성하는 디코더가 각각 존재합니다.
I love you all이 positive인지 negative인지 문장 생성과는 관계가 없으므로 디코더 파트는 상관 없습니다. 이는 encoder만으로도 충분히 동작합니다.
이를 각각 토큰단위로 나눕니다. 위치 정보를 더한 뒤 self-attention 쿼리, 키, 벨류를 추출합니다. score matrix를 만들고 이를 업데이트하는 방식으로 하면 서로 참조하면서 토큰 벡터를 업데이트 하는 것입니다.
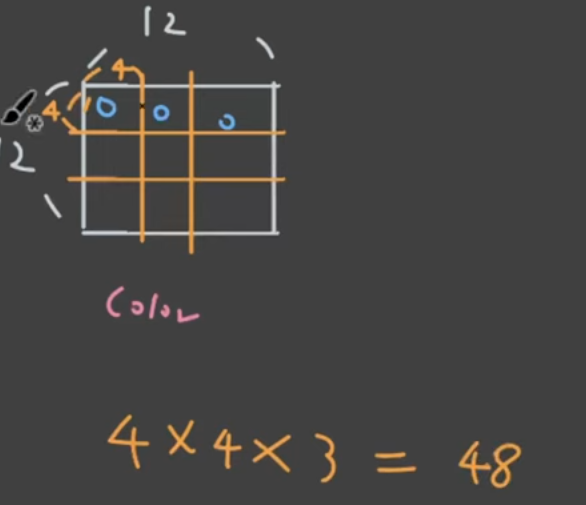
이것이 각각 linear 적용해서 1차원으로 만들어서 token으로 만듭니다. 각각 단어 토큰들에 대한 1차원 벡터가 있다면 각각의 패치를 1차원으로 반영하면 패치로 반영하는 것입니다.
self-attention으로 이미지 전체 이해 / multihead 넣어주고 몇번 반복
최종 클래스는 lass의 output vector만 가지고 classification
vlm
object detection이 VLM으로 넘어온 것, Object Detection은 class object 정해져 있음, image classification은 크래스 안에서만 classification 하는 것을 알 수 있습니다. 이미지와 언어를 이해할 수 있는 CLIP같은 모델을 바탕으로 모델을 찾을 수 있는 것을 찾을 수 있는 것입니다.
왼쪽에 있는 기린을 찾아줘 이런 걸 인식하고 알 수 있습니다.
언어로 OBJECT를 찾는 것은 Grounding DINO가 있습니다. 문장을 사용해서 검출한다면 문장으로 오브젝트를 찾을 수 있습니다. 이미지와 텍스트가 같이 INPUT으로 들어가며 이 둘을 cross attention하며 contrasive loss를 합니다.
Grounding Feature
<grounding> 태그와 함께 설명이 나오도록, 물체의 위치를 나타내는 토큰 <det> x1, y1,x2,y2 이런 걸로 모델 튜닝하는 것
텍스트로 코드를 해주면 좌표를 넘겨주는 것입니다. 캡쳐된 화면에서 물어본 곳이 위치도 찾아주며 화면을 이해하고 대화도 가능합니다.
딥시크는 하지만 모델 사이즈가 매우 큽니다. Grounding DINO는 300m, parameter를 가지고 있지만 DeepSeekv2는 moe x10, x100 그렇기에 제한된 GPU에서 파인튜닝을 하는 건 상당한 부담입니다.
DINO V2
레이블이 필요 없이
cnn, vit를 쓰던 이미지 인코더가 중요합니다. 인코더에서 나온 feature 기반으로 cat dog를 구분하므로 이를 잘 뽑아야 하는데요.
레이블이 있는 것을 사용했기에 Supervised learning이기 때문에 정해진 클래스에 맞춰서 feature가 학습됩니다.
CLIP
언어의 도움을 받아서 이미지를 학습시키는 것
clip도 결국 이미지와 - language label이 필요하기에 제한이 있을 수 있습니다. 이미지 만으로 좋은 feature를 뽑아낼 수 있으면 더 좋은 것을 만들 수 있지 않을까? 라는 것이 self-supervised-learning이라고 합니다.

같은 사이즈의 ViT입니다. x1, x2로 변환하는데 좌우가 반전된 이미지, 흑백으로 처리한 이미지 등을 넣을 수 있습니다. [CLS]토큰을 사용합니다.
SegFormer
Image Segmentation이라고 말하지만 Feature별 classification인데 가장 먼저 image segmentation problem부터 정의하자면 픽셀 단위로 classification 하는 것입니다. CNN이 매우 적극적으로 활용되었습니다.
하나의 픽셀을 보기 위해서는 이미지 전체를 보기 위해 중요하지만 CNN은 한계가 있지만 ViT는 토큰화된 이미지를 통해 attention 매커니즘이 서로를 참조하면서 전체 맥락을 이해하도록 도와줍니다.
SegFormer는 이미지가 겹치는 부분이 있도록 토큰을 만듭니다. 주어진 토큰을 모두 읽고 토큰들간의 맥락을 파악하는 과정인데 토큰 개수의 제곱에 비례하기에 연산 시간이 오래 걸립니다. 많은 연산 시간을 줄이기 위해 토큰들끼리 묶어서 연산을 한다는 개념입니다.
MLP를 통해 Classification을 하면 Seg Former입니다.
Segment Anything
SAM
어떠한 오브젝트에서 영역을 빼고 싶다고 하면 Negative를 사용합니다. CNN의 FCN, Deeplab, vit segformer를 다루어왔고 Segment Anything에 대해서 알아보면 멀티 모달이라고도 할 수 있는데 프롬프트와 범용성이 있습니다.
segment anything은 멀티 모달 모델입니다.
GPT 서비스 같은 경우 Text - image- file 등이 들어갔을 때 text가 나오고 SAM은 Image, Point, Box, Text같은 인풋을 넣으면 마스크 형태가 나오게 됩니다.
이미지와 프롬프트 인풋이 있으며 image input prompt input 그리고 decoder를 거쳐 mask가 나옵니다.
user input을 받게 되면 mask decoder로 처리합니다.
아직 정리 안하고 타이핑한 것 수정하기
'IT 프로그래밍 > AI' 카테고리의 다른 글
| [Transformer]1 (0) | 2025.05.19 |
|---|---|
| 워드임베딩 , 트랜스포머 (0) | 2025.05.19 |
| 다중분류 이진분류 요약 (0) | 2025.03.30 |
| 인공신경망은 MLE 기계 (0) | 2025.03.30 |
| [Loss function] MSE vs log-likelihood (0) | 2025.03.30 |