객체지향프로그래밍 1번

(a) 문자열을 선언하는 데 사용하는 헤더 파일은 <string>입니다.
(b) 두 개의 문자열을 합치는 연산자는 +입니다.
(c) 문자열의 길이를 반환하는 함수는 length()나 size()입니다.
(d) 문자열에서 특정 위치에 있는 문자를 가져오는 함수는 operator[]입니다.
(e) 두 개의 문자열을 비교하는 함수나 연산자로는 ==, !=, <, <=, >, >= 등이 있습니다.
(f) 문자열에서 특정 문자열을 찾는 함수는 find()입니다.
(g) 문자열에서 특정 문자열을 다른 문자열로 대체하는 함수는 replace()입니다.
(h) 문자열을 특정 문자를 기준으로 분할하는 함수는 find()를 사용하여 구현할 수 있습니다.
(i) 문자를 대문자로 변환하는 함수는 toupper()입니다.
(j) 문자를 소문자로 변환하는 함수는 tolower()입니다.
객체지향프로그래밍 2번
Hello Geeks
llo
이 코드는 문자열을 뒤집는 함수 reverseStr을 정의하고, 이 함수를 사용하여 "c++isfun" 문자열을 뒤집은 후 출력합니다. 따라서 출력 결과는 "nusfi++c"가 됩니다.
이 코드는 fun 함수를 사용하여 문자열 str에서 문자열 str1이 처음으로 발견되는 위치를 찾습니다. 그 후에 해당 위치를 출력합니다.
find 함수는 문자열 내에서 지정된 부분 문자열을 찾아 해당 문자열의 첫 번째 인덱스를 반환하며, 발견되지 않으면 npos를 반환합니다.
따라서 출력 결과는 "6"이 됩니다.
#include <iostream>
#include <string>
using namespace std;
void fun(string str, string str1)
{
unsigned int found = str.find(str1);
if (found != string::npos)
cout << found << endl;
}
int main()
{
string str{ "C++ string Quiz" };
string str1{ "string" };
fun(str, str1);
return 0;
}이 프로그램은 문자열에서 특정 부분 문자열의 인덱스를 찾는 함수를 구현한 것입니다.
fun 함수는 두 개의 문자열을 인자로 받습니다. 첫 번째 문자열 str은 대상 문자열이며, 두 번째 문자열 str1은 찾고자 하는 부분 문자열입니다.
find 함수를 사용하여 str 문자열에서 str1 부분 문자열이 처음 발견되는 위치를 찾습니다. 발견되지 않을 경우 string::npos를 반환합니다.
found 변수에 반환된 인덱스를 저장하고, 이 값을 출력합니다. 만약 str1 부분 문자열이 str 문자열 내에 존재하지 않는다면 아무것도 출력되지 않습니다.
main 함수에서는 "C++ string Quiz"라는 문자열에서 "string" 부분 문자열을 찾기 위해 fun 함수를 호출합니다.
따라서 출력은 "string"이 발견된 첫 번째 인덱스인 4가 됩니다
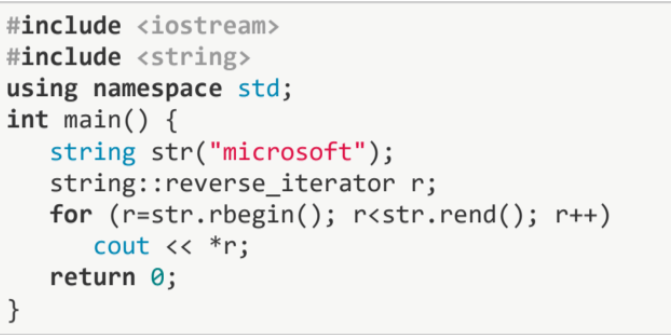
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str("microsoft");
string::reverse_iterator r;
for (r = str.rbegin(); r < str.rend(); r++)
cout << *r;
return 0;
}주어진 문자열 microsoft를 역방향으로 반복하면서 각 문자를 출력합니다. str.rbegin() 함수는 문자열의 역방향 반복자를 반환합니다. str.rend() 함수는 문자열의 역방향 반복자의 끝을 나타냅니다.
따라서 프로그램은 tfosorcim을 출력하게 됩니다.
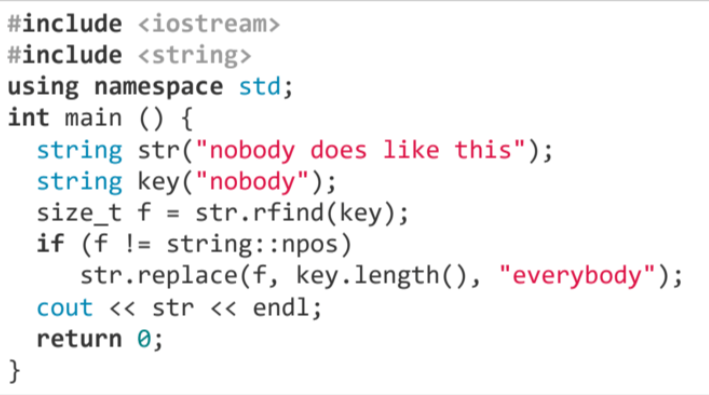
이 프로그램은 문자열에서 특정 문자열을 찾아 다른 문자열로 대체하는 것입니다.
주어진 문자열 "nobody does like this"에서 "nobody"를 찾아 "everybody"로 대체합니다. 이를 위해 rfind() 함수를 사용하여 "nobody" 문자열의 마지막 발생 위치를 찾습니다. 그런 다음 replace() 함수를 사용하여 해당 위치에서 "nobody"를 "everybody"로 대체합니다.
따라서 프로그램은 "everybody does like this"를 출력합니다.
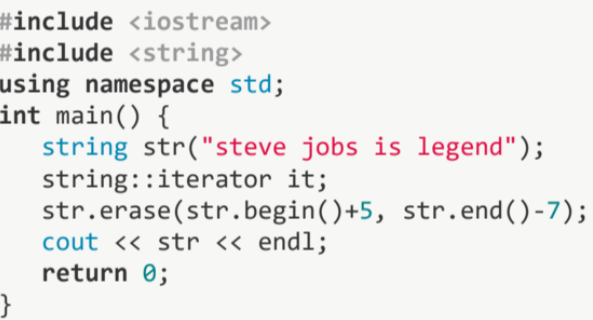
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str("steve jobs is legend");
string::iterator it;
str.erase(str.begin() + 5, str.end() - 7);
cout << str << endl;
return 0;
}이 코드는 문자열 "steve jobs is legend"에서 일부를 제거한 후 결과를 출력합니다.
str.erase(str.begin() + 5, str.end() - 7);는 문자열 str에서 5번째 위치부터 뒤에서 7번째 위치까지의 문자열을 제거합니다. 따라서 "jobs is" 부분이 제거되고, "steve legend"만 남게 됩니다. 이후 cout << str << endl; 구문에 의해 "steve legend"가 출력됩니다.
객체지향프로그래밍 3번

#include <iostream>
#include <string>
#include <cctype>
using namespace std;
int firstOccurrence(string str, string target) {
// 소문자로 변환
for (char& c : str) {
c = tolower(c);
}
for (char& c : target) {
c = tolower(c);
}
size_t found = str.find(target); // 첫 번째로 등장하는 위치 찾기
if (found != string::npos) {
return found; // 위치 반환
}
else {
return -1; // 등장하지 않을 경우 -1 반환
}
}
int main() {
string str1 = "abCdefg";
string str2 = "cdE";
cout << firstOccurrence(str1, str2) << endl;
// 2 출력 (0부터 시작하는 인덱스)
return 0;
}이 코드는 firstOccurrence라는 함수를 정의합니다. 이 함수는 두 개의 문자열을 매개변수로 받습니다. 첫 번째 문자열은 str이라는 변수에, 두 번째 문자열은 target이라는 변수에 저장됩니다.
그 후, str 문자열과 target 문자열의 모든 문자를 소문자로 변환하여 대소문자를 구분하지 않고 비교할 수 있도록 합니다.
그 다음, str 문자열에서 target 문자열이 처음으로 등장하는 위치를 찾기 위해 find 함수를 사용합니다. 만약 target 문자열이 str에 존재한다면, 해당 위치를 반환하고, 존재하지 않는다면 -1을 반환합니다.
main 함수에서는 예시 문자열 str1과 str2를 정의하고, firstOccurrence 함수를 호출하여 두 번째 문자열이 등장하는 위치를 출력합니다.
객체지향프로그래밍 4번

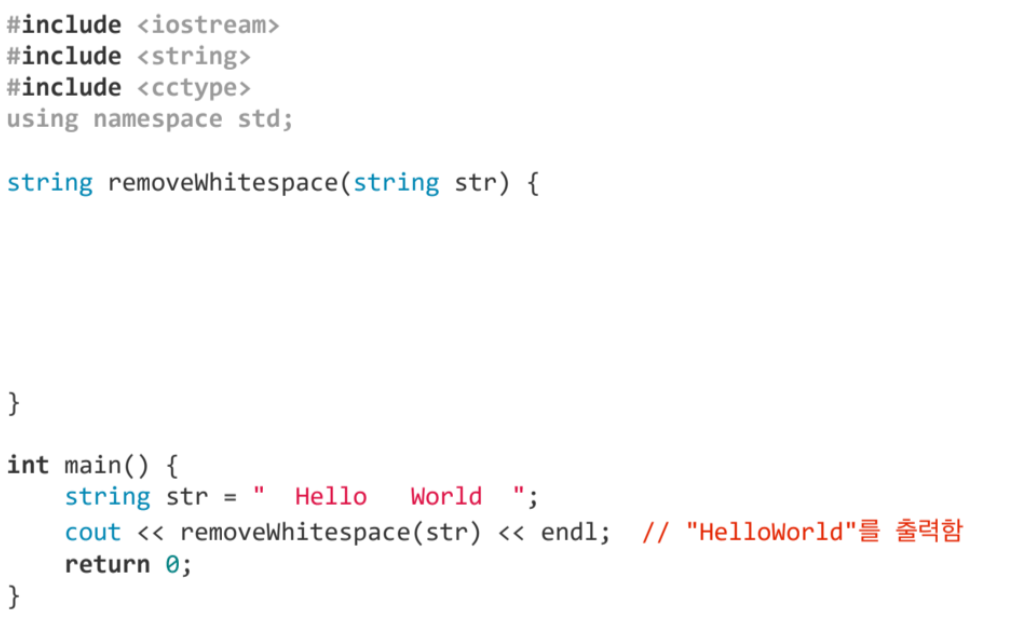
#include <iostream>
#include <string>
#include <cctype>
using namespace std;
string removeWhitespace(string str)
{
string result = "";
for (char c : str)
{
if (!isspace(c))
{
result += c;
}
}
return result;
}
int main()
{
string str = " Hello World ";
cout << removeWhitespace(str) << endl;
return 0;
}객체지향프로그래밍 5번

erase를 통해 공백 제거 방법
#include <iostream>
#include <string>
#include <cctype>
#include <algorithm>
using namespace std;
string removeWhitespace(string str)
{
for (int i = 0; i < str.size(); i++)
{
str.erase(std::remove(str.begin(), str.end(), ' '), str.end());
str.erase(std::remove(str.begin(), str.end(), ' '), str.end());
}
return str;
}
int main()
{
string str = " Hello world ";
cout << removeWhitespace(str) << endl; // HelloWorld 출력
return 0;
}erase를 통해서 제거를 해주는 방식입니다. for문을 통해서 반복을 진행해줬습니다.
먼저 erase의 사용법을 알려면 remove의 사용을 알아야 하는데요.
revmoe(str.begin(), str.end(), ' ') 이런 식으로 해주면 ' ' 즉 공백을 문자열의 맨 끝으로 보내주게 됩니다. 그리고 remove에는 해당 문자를 가리키는 주소가 리턴이 되게 됩니다.
str.erase(std::remove(str.begin(), str.end(), ' '), str.end());이 함수는 주어진 문자열 범위에는 공백을 찾아 문자열 뒤로 이동시키기 때문에
erase(remove, str.end()); 이렇게 되면 erase()함수는 시작 위치부터 끝 위치까지의 범위를 받아들이고 해당 범위에 있는 요소를 삭제합니다. 여기에선 remove()함수에서 공백을 뒤로 이동시킨 뒤에 그 이후의 요소를 삭제하기 위해 사용됩니다.
따라서 erase()함수는 이동된 공백을 제거하여 최종적으로 문자열에서 모든 공백을 삭제합니다.
이것이 작동하는 이유는 remove()는 함수의 특정 값으로 반환하고 그 후에 이동된 요소를 삭제하기 위해 erase(remove(), end()) 이렇게 해주면 remove로 return된 특정 값부터 end()까지 삭제되어서 최종적으로 문자열에서 공백이 제거됩니다.
화문인지 확인하는 함수
#include <iostream>
#include <string>
using namespace std;
bool isPalindrome(string str)
{
for (int i = 0; i < str.size()/2; i++)
{
if (str[i] == str[str.size() - i -1])
continue;
else
{
return false;
}
}
return true;
}
int main()
{
string str = "racecar";
cout << isPalindrome(str) << endl;
return 0;
}
bool isPalindrome(string str)
{
int start = 0;
int end = str.length() - 1;
while (start < end)
{
if (str[start] != str[end])
{
return false;
}
start++;
end--;
}
return true;
}
객체지향프로그래밍 6번

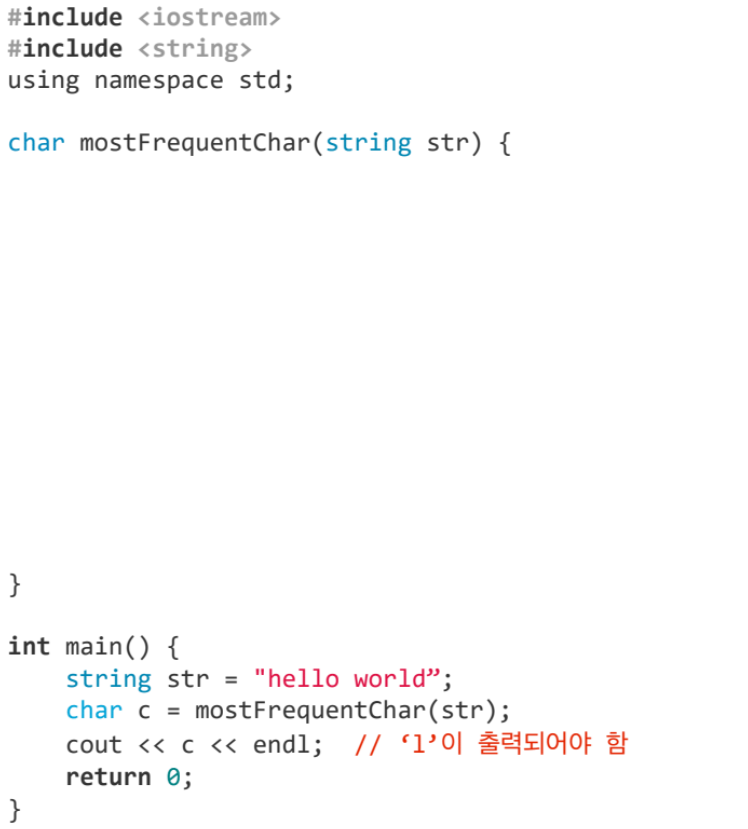
#include <iostream>
#include <string>
using namespace std;
char mostFrequentChar(string str) {
// 알파벳 소문자만을 고려하여 빈도를 저장할 배열을 초기화합니다.
int freq[26] = {0}; // 알파벳 26개에 대한 빈도를 저장합니다.
// 문자열을 순회하며 각 문자의 빈도를 계산합니다.
for (char ch : str) {
// 알파벳 소문자만 고려합니다.
if (ch >= 'a' && ch <= 'z') {
freq[ch - 'a']++; // 해당 문자의 빈도를 증가시킵니다.
}
}
// 가장 빈도가 높은 문자를 찾습니다.
char mostFreqChar = 'a'; // 가장 빈도가 높은 문자를 기본값으로 설정합니다.
int maxFreq = 0; // 최대 빈도를 저장합니다.
for (int i = 0; i < 26; i++) {
if (freq[i] > maxFreq) {
maxFreq = freq[i];
mostFreqChar = 'a' + i; // 최대 빈도를 가진 문자를 업데이트합니다.
}
}
return mostFreqChar;
}
int main() {
string str = "hello world";
char c = mostFrequentChar(str);
cout << c << endl; // ‘l’
return 0;
}
객체지향프로그래밍 7번

#include <iostream>
#include <string>
using namespace std;
bool isAnagram(string str1, string str2)
{
for (int i = 0; i < str1.size() -1; i++)
{
for (int j = 0; j < str1.size() - i-1; j++)
{
int temp;
if (str1[j] > str1[j + 1])
{
temp = str1[j];
str1[j] = str1[j + 1];
str1[j + 1] = temp;
}
}
}
for (int i = 0; i < str2.size() - 1; i++)
{
for (int j = 0; j < str2.size() - i - 1; j++)
{
int temp;
if (str2[j] > str2[j + 1])
{
temp = str2[j];
str2[j] = str2[j + 1];
str2[j + 1] = temp;
}
}
}
if (str1 == str2)
{
return true;
}
else
return false;
}
int main()
{
string str1 = "listen";
string str2 = "silent";
cout << isAnagram(str1, str2) << endl;
return 0;
}
isAnagram 함수는 두 개의 문자열을 매개변수로 받습니다.
두 문자열을 각각 정렬하기 위해 두 개의 중첩된 반복문을 사용합니다. 버블 정렬을 사용하여 문자열의 각 문자들을 오름차순으로 정렬합니다.
정렬된 문자열을 비교하여 같으면 true를 반환하고, 그렇지 않으면 false를 반환합니다.
main 함수에서는 "listen"과 "silent"라는 두 문자열을 isAnagram 함수에 전달하여 결과를 출력합니다.
이 코드는 주어진 두 문자열이 애너그램인지를 비교하기 위해 간단한 방법을 사용합니다. 하지만 더 효율적인 방법으로는 문자열에 포함된 각 문자의 빈도를 계산하고, 이 빈도를 비교하여 애너그램 여부를 확인하는 방법이 있습니다. 이렇게 하면 문자열의 길이에 관계없이 더 효율적으로 애너그램 여부를 확인할 수 있습니다.
객체지향프로그래밍 8번
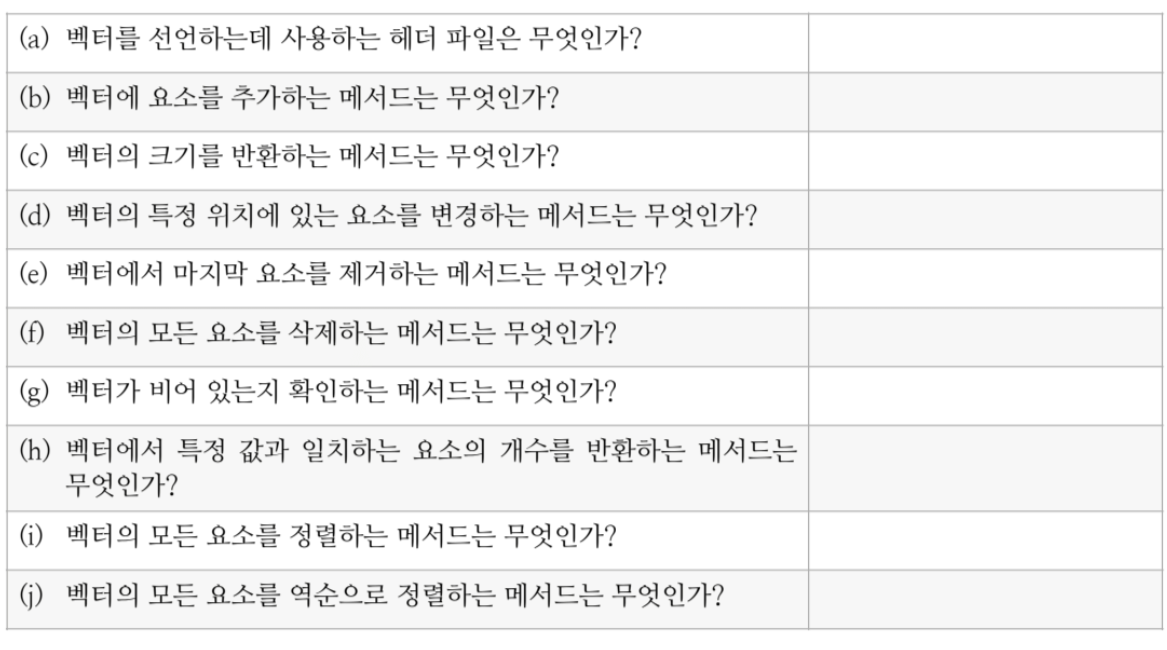
a) 벡터를 선언하는데 사용하는 헤더 파일은 <vector>입니다.
(b) 벡터에 요소를 추가하는 메서드는 push_back입니다.
(c) 벡터의 크기를 반환하는 메서드는 size입니다.
(d) 벡터의 특정 위치에 있는 요소를 변경하는 메서드는 operator[]나 at 메서드를 사용할 수 있습니다.
(e) 벡터에서 마지막 요소를 제거하는 메서드는 pop_back입니다.
(f) 벡터의 모든 요소를 삭제하는 메서드는 clear입니다.
(g) 벡터가 비어 있는지 확인하는 메서드는 empty입니다.
(h) 벡터에서 특정 값과 일치하는 요소의 개수를 반환하는 메서드는 count입니다.
(i) 벡터의 모든 요소를 정렬하는 메서드는 sort입니다.
(j) 벡터의 모든 요소를 역순으로 정렬하는 메서드는 reverse입니다.
객체지향프로그래밍 9번

#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v;
for (int i = 1; i <= 5; i++)
v.push_back(i);
vector<int>::iterator it = v.begin();
*it = 3;
for (it = v.begin(); it != v.end(); ++it)
cout << *it << " ";
return 0;
}이 코드는 벡터를 사용하여 정수를 저장하고, 벡터의 첫 번째 요소를 3으로 변경한 후 모든 요소를 출력합니다.
주요 내용은 다음과 같습니다:
<iostream>과 <vector> 헤더 파일을 포함하여 필요한 라이브러리를 사용합니다.
main 함수에서 정수를 저장하기 위한 빈 벡터 v를 선언합니다.
반복문을 사용하여 1부터 5까지의 정수를 v 벡터에 추가합니다. push_back 메서드를 사용하여 각 정수를 벡터에 추가합니다.
vector<int>::iterator it을 사용하여 벡터 v의 iterator를 생성하고, 이를 벡터의 시작 지점을 가리키도록 합니다.
*it = 3;을 통해 첫 번째 요소를 3으로 변경합니다. 벡터의 첫 번째 요소를 가리키는 iterator인 it이므로 해당 요소를 변경합니다.
이후 반복문을 사용하여 it iterator를 사용하여 벡터의 모든 요소를 출력합니다. it을 v.begin()에서 시작하여 v.end()에 도달할 때까지 증가시키면서 각 요소를 출력합니다.
결과적으로, 출력은 "3 2 3 4 5"가 될 것입니다. 첫 번째 요소가 3으로 변경되었으므로 첫 번째 요소가 3이 되고, 나머지 요소는 추가된 순서대로 출력됩니다.
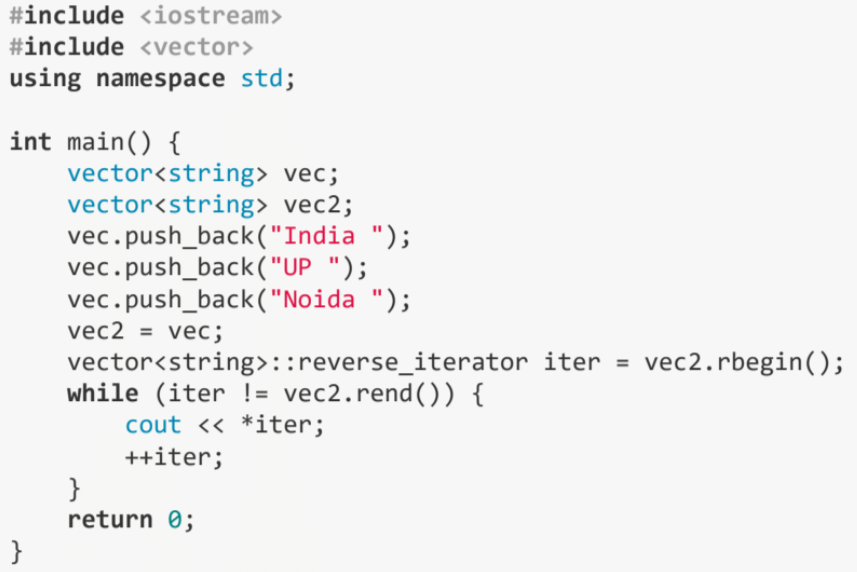
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<string> vec;
vector<string> vec2;
vec.push_back("India ");
vec.push_back("Up ");
vec.push_back("Nodia ");
vec2 = vec;
vector<string>::reverse_iterator iter = vec2.rbegin();
while (iter != vec2.rend())
{
cout << *iter;
++iter;
}
return 0;
}<iostream>과 <vector> 헤더 파일을 포함하여 필요한 라이브러리를 사용합니다.
main 함수에서 두 개의 빈 문자열 벡터 vec와 vec2를 선언합니다.
vec 벡터에 "India", "Up", "Nodia" 문자열을 순서대로 추가합니다.
vec2 = vec;를 통해 vec 벡터의 내용을 vec2 벡터에 복사합니다.
vector<string>::reverse_iterator iter = vec2.rbegin();를 사용하여 vec2 벡터의 역방향 반복자를 생성합니다. 이는 vec2 벡터의 끝부터 시작하여 역순으로 이동할 수 있도록 해줍니다.
while (iter != vec2.rend()) 반복문을 사용하여 역순으로 벡터의 요소를 출력합니다. rend()는 역방향 반복자의 끝을 나타내므로, iter가 벡터의 역방향 끝에 도달할 때까지 반복합니다.
각 요소를 출력한 후에는 반복자를 다음 요소로 이동시킵니다. 역순 반복자이므로 ++iter를 통해 이전 요소로 이동합니다.
결과적으로, 출력은 "Nodia Up India"가 될 것입니다. vec 벡터의 내용이 vec2에 복사되었으며, vec2의 역순 반복자를 사용하여 역순으로 출력되었습니다.

<iostream>과 <vector> 헤더 파일을 포함하여 필요한 라이브러리를 사용합니다.
main 함수에서 두 개의 빈 정수 벡터 v1과 v2를 선언합니다.
v1 벡터에 순서대로 1, 2, 3, 4를 추가합니다.
v2 벡터에 순서대로 5, 6, 7, 8을 추가합니다.
v1.swap(v2);를 통해 두 벡터의 내용을 서로 교환합니다. 이렇게 하면 v1에는 5, 6, 7, 8이 저장되고, v2에는 1, 2, 3, 4가 저장됩니다.
반복문을 사용하여 v2 벡터의 요소를 출력합니다. v2 벡터의 요소는 이제 1, 2, 3, 4로 바뀌었으므로 이를 출력합니다.
결과적으로, 출력은 "5 6 7 8"이 될 것입니다. v2 벡터의 요소는 v1 벡터와 교환되었으므로, v2 벡터에는 1, 2, 3, 4가 저장되어 출력됩니다.

이 코드는 두 개의 정수 벡터를 생성하고, 두 벡터가 서로 같은지를 비교하여 결과를 출력하는 예제입니다.
주요 내용은 다음과 같습니다:
<iostream>과 <vector> 헤더 파일을 포함하여 필요한 라이브러리를 사용합니다.
main 함수에서 두 개의 빈 정수 벡터 v1과 v2를 선언합니다.
v1 벡터에 순서대로 1, 2, 3, 4를 추가합니다.
v2 벡터에도 순서대로 1, 2, 3, 4를 추가합니다. 따라서 두 벡터는 같은 요소를 가지고 있습니다.
if (v1 == v2)를 통해 두 벡터가 서로 같은지를 비교합니다. 두 벡터가 같으면 "both are equal"을 출력하고, 그렇지 않으면 "both are not equal"을 출력합니다.
결과적으로, 두 벡터가 서로 같기 때문에 "both are equal"이 출력될 것입니다.

이 출력 결과를 확인해보니 "4 5 7 8 9 10"이 출력되었습니다. 이는 프로그램이 제대로 동작하여 기대한 대로 벡터의 요소를 제거한 후 남은 요소들을 출력한 것입니다.
이 코드에서 벡터의 요소를 제거하는 부분을 다시 살펴보겠습니다:
vec.erase(vec.begin() + 5);: 인덱스가 5인 요소를 제거합니다. 벡터의 인덱스는 0부터 시작하므로, 실제로 6번째 요소가 제거됩니다.
vec.erase(vec.begin(), vec.begin() + 3);: 벡터의 시작부터 세 번째 요소까지를 제거합니다. 따라서 1번째부터 3번째 요소가 제거됩니다.
따라서 "1 2 3 4 5 6 7 8 9 10"에서 6번째 요소인 6과 1번째부터 3번째 요소인 1, 2, 3이 제거되어 "4 5 7 8 9 10"이 출력된 것입니다. 프로그램이 예상대로 작동하여 올바른 결과를 출력한 것으로 보입니다.
객체지향프로그래밍 10번

#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> nums = {1, 2, 3, 2, 4, 5, 3, 6};
// 벡터를 순회하면서 홀수를 제거하는 방식으로 수정
for (auto it = nums.begin(); it != nums.end();) {
if (*it % 2 != 0) {
it = nums.erase(it); // erase 함수는 제거된 요소의 다음 위치를 반환함
} else {
++it; // 홀수가 아닌 경우 다음 요소로 이동
}
}
for (int num : nums) {
cout << num << " ";
}
cout << endl;
return 0;
}이 코드는 반복문을 사용하여 벡터를 순회하면서 홀수를 발견하면 해당 요소를 제거합니다. 이때 erase 함수를 사용하여 요소를 제거하고, 제거된 요소의 다음 위치를 반환하도록 합니다. 이렇게 함으로써 반복자가 올바르게 관리됩니다. 수정된 코드는 주어진 목적에 맞게 모든 홀수를 제거하고 "2 2 4 6"을 출력합니다
주어진 코드에서 문제는 반복자를 잘못 사용하여 벡터의 요소를 제거한 후에도 올바르게 반복자를 증가시키지 않았다는 점입니다. 이로 인해 반복자가 제거된 요소를 가리키게 되어 예기치 않은 동작이 발생했습니다.
원래 코드에서는 erase 함수를 사용하여 홀수를 발견한 후에는 it 반복자를 증가시키지 않고 다음 요소를 가리키게 하였습니다. 그 결과, 홀수가 제거된 후에도 it 반복자는 이전에 제거된 요소를 가리키게 되었고, 이는 예상치 못한 결과를 초래했습니다.
수정된 코드에서는 홀수를 발견한 후에도 erase 함수를 통해 제거한 요소의 다음 위치를 반복자에 저장하고, 이를 사용하여 반복자를 올바르게 증가시킴으로써 이 문제를 해결했습니다.
객체지향프로그래밍 11번


#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> removeDuplicates(vector<int> nums)
{
// 벡터를 정렬하여 중복된 숫자들을 인접하게 만듦
sort(nums.begin(), nums.end());
// 중복된 요소들을 벡터의 끝으로 이동하고, 중복된 요소들의 시작을 반환
auto it = unique(nums.begin(), nums.end());
// 중복된 요소들을 벡터에서 삭제
nums.erase(it, nums.end());
return nums;
}
int main()
{
vector<int> nums = { 1, 2, 3, 2, 4, 5, 3, 6 };
vector<int> result = removeDuplicates(nums);
for (int num : result)
cout << num << " ";
cout << endl;
return 0;
}
객체지향프로그래밍 12번

이 문제를 해결하기 위해서는 두 개의 벡터를 합집합으로 결합하고 중복된 원소를 제거한 후 새로운 벡터를 반환해야 합니다. 이를 위해 다음과 같은 접근 방법을 사용할 수 있습니다:
두 개의 입력 벡터를 합칩니다.
합친 벡터를 정렬합니다.
중복된 요소를 제거합니다.
중복된 요소가 제거된 벡터를 반환합니다.
이러한 방법을 따라 구현된 함수는 다음과 같습니다:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> unionVectors(vector<int> nums1, vector<int> nums2) {
// 두 벡터를 합침
vector<int> combined;
combined.reserve(nums1.size() + nums2.size()); // 벡터의 크기를 미리 할당하여 성능을 향상시킴
combined.insert(combined.end(), nums1.begin(), nums1.end());
combined.insert(combined.end(), nums2.begin(), nums2.end());
// 합친 벡터를 정렬하여 중복된 요소를 제거
sort(combined.begin(), combined.end());
auto it = unique(combined.begin(), combined.end());
combined.erase(it, combined.end());
return combined;
}
int main() {
vector<int> nums1 = { 1, 2, 3 };
vector<int> nums2 = { 3, 4, 5 };
vector<int> result = unionVectors(nums1, nums2);
for (int num : result)
cout << num << " ";
cout << endl;
return 0;
}'IT 프로그래밍 > 객체지향프로그래밍' 카테고리의 다른 글
| 객체지향프로그래밍 과제3 총정리 (0) | 2024.04.21 |
|---|---|
| 객체지향프로그래밍 3과 그룹액티비티 총정리 (0) | 2024.04.21 |
| 객체지향프로그래밍 그룹 액티비티 1과 총정리 (0) | 2024.04.21 |
| 객체지향프로그래밍 1번, 2번, 3번, 4번, 5번, 6번 (0) | 2024.04.20 |
| 객체지향 프로그래밍 25번 , 26번, 28번, 29번, 30번, 31번, 32번, 33번 (0) | 2024.04.20 |