
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int compare_lex(int a, int b)
{
int p = 1, q = 1;
while (p * 10 <= a) p *= 10;
while (p * 10 <= b) q *= 10;
while (p > 0 && q > 0) {
int d1 = a / p, d2 = b / q;
a %= p, b %= q;
if (d1 < d2) return -1;
else if (d1 > d2) return 1;
p /= 10, q /= 10;
}
if (p > 0) return 1;
if (q > 0) return -1;
return 0;
}
int main()
{
vector<int> numbers;
int n, k;
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> k;
numbers.push_back(k);
}
for (int i = n - 1; i > 0; i--)
{
for (int j = 0; j < i; j++)
{
if (compare_lex(numbers.at(j), numbers.at(j+1)) > 0)
swap(numbers[j], numbers[j+1]);
}
for (int i = 0; i < n; i++)
cout << numbers.at(i) << ' ';
}
return 0;
}먼저 compare_lex 함수에 대해서 설명을 하겠습니다. a와 b의 자릿수를 비교하기 위해 10의 거듭제곱을 사용합니다. 루프를 통해 각 정수의 자릿수에 해당하는 p와 q를 찾습니다. p와 q는 각각 a와 b의 가장 높은 자릿수를 나타냅니다.
이후에는 가장 높은 자릿수부터 시작하여 비교를 수행합니다. 각 자릿수의 값을 추출하고 해당 자릿수의 값을 비교하여 두 정수를 사전식으로 비교합니다.
만약 두 정수의 자릿수가 다르다면, 더 높은 자릿수를 가진 정수가 더 큰 값으로 판단합니다.
만약 두 정수의 자릿수가 같다면, 각 자릿수를 하나씩 비교하여 사전식으로 더 작은 값인 경우 -1, 더 큰 값인 경우 1을 반환합니다. 만약 두 정수가 동일하다면 0을 반환합니다.

먼저 getline(cin, line)을 통해 사용자로부터 한 줄을 입력받습니다. 입력받은 문자열이 "exit" 일 경우 프로그램을 종료합니다. for 루프를 사용하여 문자열을 순회합니다.
isspace(line[i])는 line의 i번째 문자가 공백인지를 확인합니다. i == 0 || isspace(line[i-1])) 는 현재 문자가 첫 번째 문자이거나 이전 문자가 공백인 경우를 확인합니다. 이 경우에 현재 문자를 제거하여 연속된 공백을 제거합니다.
마지막 공백을 제거하기 위해 if (isspace(line[line.length() -1])) 을 사용합니다. 최종적으로 정리된 문자열과 해당 문자열의 길이를 출력합니다.
이 코드는 사용자가 입력한 문자열에서 연속된 공백을 제거하고, 마지막에 있는 공백도 제거한 후에 문자열의 길이를 출력합니다. 이를 통해 사용자가 입력한 문자열의 공백을 정리하여 보다 깔끔하게 표시할 수 있습니다.

#include <iostream>
#include <sstream>
#include <string>
#include <vector>
#include <cctype>
using namespace std;
vector<pair<string, int>> word_counters;
void tolowercase(string& str)
{
for (char& c : str)
c = tolower(c);
}
int main()
{
string word;
ifstream infile("input3.txt");
while (infile >> word)
{
tolowercase(word);
bool found = false;
for (pair<string, int>& item : word_counters)
{
if (item.first == word)
{
item.second++;
found = true;
break;
}
}
if (!found)
{
pair<string, int> t(word, 1);
word_counters.push_back(t);
}
}
infile.close();
for (int i = word_counters.size() - 1; i > 0; i--)
{
for (int j = 0; j < i; j++)
{
if (word_counters.at(j).second > word_counters.at(j + 1).second)
swap(word_counters.at(j), word_counters.at(j + 1));
}
}
for (pair<string, int>& item : word_counters)
cout << item.first << ' ' << item.second << endl;
return 0;
}
이 코드는 파일에서 단어를 읽어와서 각 단어의 출현 빈도를 계산하고, 빈도가 높은 순으로 정렬하여 출력하는 프로그램입니다. 이를 위해 pair와 vector를 사용합니다.
여기서 pair<string, int>는 두 가지 타입을 함께 묶어서 저장할 수 있는 구조체입니다. 첫 번째 타입은 문자열이고 두 번째 타입은 정수입니다. 이것을 사용하는 이유는 해당 단어의 출현 횟수를 하나의 묶음으로 관리하기 위해서입니다.
그리고 vector<pair<string, int>> 는 pair<string, int> 를 원소로 가지는 동적 배열을 의미합니다. 이렇게 사용하면 여러 개의 단어와 그에 해당하는 출현 횟수를 저장할 수 있습니다.
이제 코드를 단계별로 설명해보겠습니다.
1. tolowercase()함수는 문자열을 소문자로 변환하는 함수입니다. 이 함수는 주어진 문자열의 모든 문자를 소문자로 변경합니다.
2. main 함수에서는 먼저 파일에서 단어를 읽어오고 각 단어를 소문자로 변환하여 처리합니다. 그리고 각 단어의 출현 횟수를 저장히기 위한 word_counters 벡터를 정의합니다.
3. 파일에서 단어를 읽어와서 소문자로 변환한 뒤, word_counters 벡터에 해당 단어와 출현 횟수를 저장합니다. 이미 등록된 단어라면 해당 단어의 출현 횟수를 증가시키고, 새로운 단어라면 새로운 pair을 생성하여 owrd_counters에 추가합니다.
4. word_counters에 저장된 단어들을 빈도순으로 정렬합니다. 이는 버블 sort를 사용합니다.
5. 정렬된 결과를 순회하여 각 단어와 해당 단어의 출현 횟수를 출력합니다.

#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
getline(cin, s);
int sum = 0, start = 0, pos = 0;
if (s[0] == '+' || s[0] == '-')
pos = 1;
while (true)
{
int idx = s.find_first_of("+-", pos);
if (idx == -1)
{
string part = s.substr(start);
if (part == "") break;
sum += stoi(part);
break;
}
int count = idx - start;
string part = s.substr(start, count);
sum += stoi(part);
pos = idx + 1;
start = idx;
}
cout << "The sum is " << sum << endl;
return 0;
}
getline(cin, s)는 사용자로부터 한 줄을 입력받아서 문자열 's'에 저장합니다. if (s[0] == '+' || s[0] == '0') pos = 1;은 문자열의 첫 번째 문자가 +나 -일 경우에는 숫자가 양수 또는 음수일 수 있으므로 시작 위치를 1로 설정합니다.
while (true) { } 무한루프를 시작합니다. 루프 내부에서는 문자열에서 +나 -를 찾아 숫자를 출력하고 합을 계산합니다.
int idx = s.find_fist_of("+-", pos); pos 위치부터 +나 -를 찾아서 해당 인덱스에 변환합니다.
if (idx == -1 ) { ... } 는 더 이상 +나 -를 찾을 수 없을 때 남은 부분 문자열을 출력하여 숫자로 변환하여 합을 더합니다.
int count = idx - start;는 +나 -가 발견된 위치까지의 문자 개수를 계산합니다.
string part = s.substr(start, count); 시작 위치부터 count만큼의 부분 문자열을 추출하여 part에 저장합니다.
sum += stoi(part)를 통해 추출된 부분 문자열을 정수로 변환하여 합에 더합니다.
pos = idx+1; 다음 검색을 위해 +나 -가 발견된 위치보다 한 칸 뒤부터 검색을 시작합니다.
start = idx; 다음 검색을 위해 시작 위치를 +나 -가 발견된 위치로 업데이트 합니다.

#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <cctype>
using namespace std;
vector<vector<string>> lines;
void tolowercase(string& str) {
for (char& c : str)
c = tolower(c);
}
vector<string> split_line(string& line) {
vector<string> tokens;
int start = 0, end;
while ((end = line.find(' ', start)) != -1) {
string t = line.substr(start, end - start);
if (t.size() > 0)
tokens.push_back(t);
start = end + 1;
}
string t = line.substr(start);
if (t.size() > 0)
tokens.push_back(line.substr(start));
return tokens;
}
void print_line(vector<string>& item) {
for (auto t : item) {
cout << t << ' ';
}
cout << ':' << item.size() << endl;
}
int main() {
string line;
ifstream infile("sample_lines.txt");
while (getline(infile, line)) {
vector<string> tokens = split_line(line);
if (tokens.size() > 0)
lines.push_back(tokens);
}
infile.close();
for (int i = lines.size() - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
if (lines.at(j).size() < lines.at(j + 1).size())
swap(lines.at(j), lines.at(j + 1));
}
}
for (auto& item : lines) {
print_line(item);
}
return 0;
}

#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <cctype>
#include <algorithm>
using namespace std;
vector<string> words;
int main()
{
string str;
ifstream infile("sample.txt");
while (infile >> str)
{
int s = 0, t = str.length() - 1;
while (s < str.length() && !isalnum(str[s]))
s++;
while (t >= 0 && !isalnum(str[t]))
t--;
if (s <= t)
{
string pure_word = str.substr(s, t - s + 1);
for (int i = 0; i < pure_word.length(); i++)
pure_word[i] = tolower(pure_word[i]);
auto it = words.begin();
while (it != words.end() && *it < pure_word)
it++;
if(it != words.end() && *it == pure_word)
continue;
words.insert(it, pure_word);
}
}
infile.close();
for (auto w : words)
cout << w << endl;
return 0;
}1. ifstream infile("sample"txt"); 은 sample.txt파일을 읽기 모드로 열어서 파일 스트림 infile에 연결합니다.
2. while(infile >> str) { ... } 은 파일에서 한 번에 한 단어씩 읽어옵니다. 이때, 파일에서 읽어온 문자열을 'str'에 저장합니다.
3. while(s < str.length() && !isalnum(str[s])) s++; 문자열의 시작부터 숫자나 알파벳이 나올 때까지 인덱스를 찾습니다. 즉, 단어의 앞쪽에 있는 특수문자와 공백은 무시합니다.
4. while(t >=0 && !isalnum(str[t])) t-- : 문자열의 긑부터 숫자나 알파벳이 나올 때까지의 인덱스를 찾습니다. 즉 단어의 뒷쪽에 있는 특수문자나 공백을 무시합니다.
5. 'string pure_wordcd = str.substr(s, t-s+1); 알파벳과 숫자로만 이루어진 단어를 추출합니다.
6. for(int i=0; i<pure_word.length(); i++) pure_word[i] = tolower(pure_word[i]); 추출된 문자를 tolower 즉 소문자로 변환합니다.
7. auto it = words.begin(); while(it != words.end() && *it < pure_word) it++; 정렬된 words 벡터에서 새로운 단어를 삽입할 위치를 찾습니다.
8. if(it != words.end() && *it == [pure_word) continue; 이미 존재하는 단어인 경우엔 건너뜁니다.

#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
vector<string> words;
int main() {
string str;
while(1) {
cin >> str;
if (str == "exit") break;
auto it = words.begin();
while(it != words.end() && *it < str)
it++;
if (it != words.end() && *it==str) {
cout << "duplicate" << endl;
continue;
}
words.insert(it, str);
for (auto w: words)
cout << w << ' ';
cout << endl;
}
return 0;
}이 코드는 사용자로부터 단어를 입력받아 정렬된 순서로 저장하고, 중복된 단어가 입력될 경우 "duplicate"를 출력하는 프로그램입니다. 코드의 동작과 함께 사용된 요소들을 살펴보겠습니다.
헤더 파일 포함: #include <iostream>, #include <string>, #include <vector>, #include <algorithm>은 각각 입력/출력, 문자열 처리, 벡터 컨테이너, 정렬 알고리즘을 사용하기 위한 헤더 파일을 포함합니다.
using namespace std;: std 네임스페이스를 사용합니다.
vector<string> words;: 문자열을 저장할 벡터 words를 선언합니다.
int main() { ... }: 프로그램의 진입점을 정의합니다.
string str;: 문자열을 저장할 변수 str을 선언합니다.
while(1) { ... }: 무한 루프를 시작합니다.
cin >> str;: 사용자로부터 문자열을 입력받습니다.
if (str == "exit") break;: 사용자가 "exit"을 입력하면 무한 루프를 탈출합니다.
auto it = words.begin();: words 벡터의 시작점을 가리키는 반복자 it을 선언합니다.
while(it != words.end() && *it < str) it++;: it이 words의 끝에 도달하거나, *it이 str보다 크거나 같을 때까지 it을 증가시킵니다. 이는 words 벡터에서 str보다 크거나 같은 첫 번째 원소를 찾는 것입니다.
if (it != words.end() && *it==str) { cout << "duplicate" << endl; continue; }: it이 words 벡터의 끝이 아니고, *it이 str과 같은 경우에 "duplicate"를 출력하고, 다음 반복을 진행합니다.
words.insert(it, str);: words 벡터에 str을 삽입합니다. it이 가리키는 위치에 삽입됩니다.
for (auto w: words) cout << w << ' ';: 벡터 words의 모든 원소를 출력합니다.
cout << endl;: 한 번의 입력에 대한 결과를 출력한 후 줄을 바꿉니다.
return 0;: main() 함수의 반환 값으로 0을 반환하여 프로그램이 성공적으로 종료되었음을 나타냅니다.
이 코드는 사용자가 입력한 단어를 정렬된 순서로 저장하고, 중복된 단어가 입력될 경우 "duplicate"를 출력합니다. 추가적인 입력과 반복을 통해 계속해서 단어를 받고 출력하며, "exit"을 입력하면 프로그램이 종료됩니다.
words.insert(it, str);는 vector에 원소를 삽입하는 함수입니다. 여기서 it은 삽입할 위치를 가리키는 반복자(iterator)이며, str은 삽입할 값입니다. 이 함수는 vector의 특정 위치에 새로운 값을 삽입합니다.
만약 it이 vector의 시작점인 begin()을 가리키고 있다면, str은 vector의 맨 앞에 삽입됩니다. 만약 it이 vector의 끝점인 end()를 가리키고 있다면, str은 vector의 끝에 삽입됩니다. 그렇지 않은 경우에는 it이 가리키는 위치에 str이 삽입되고, 기존의 값들은 it 이후로 한 칸씩 뒤로 밀립니다.
이 함수를 사용하여 새로운 값을 특정 위치에 삽입할 수 있습니다. 이 코드에서는 it이 찾아진 위치에 str을 삽입하여, 입력된 단어를 정렬된 순서로 유지하고 있습니다.

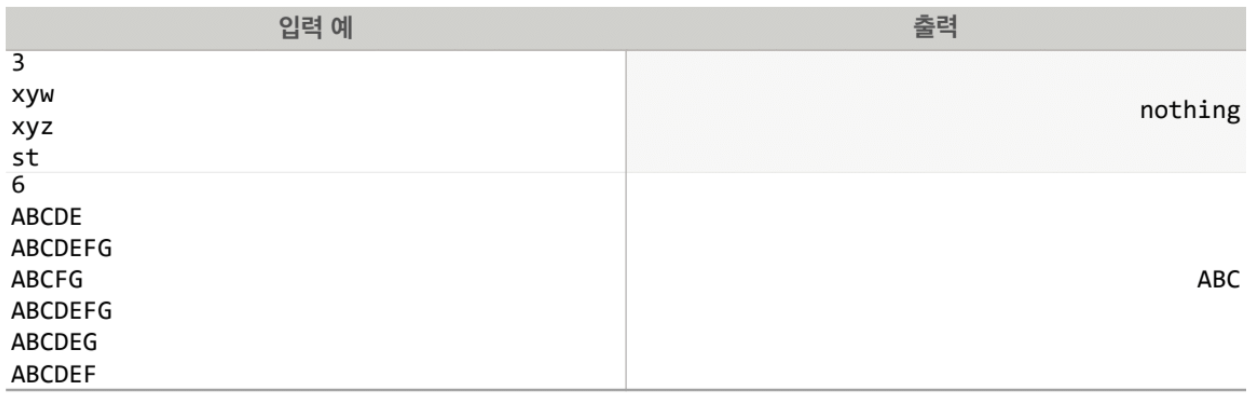
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
vector<string> words;
int len_common_prefix(string a, string b) {
for (int i=0; i<min(a.length(), b.length()); i++)
if (a[i] != b[i])
return i;
return min(a.length(), b.length());
}
int main() {
string str;
int n;
cin >> n;
for (int i=0; i<n; i++) {
cin >> str;
words.push_back(str);
}
string prefix = words[0];
int len = prefix.length();
for (int i=1; i<n && len > 0; i++) {
int len = len_common_prefix(prefix, words[i]);
prefix = prefix.substr(0, len);
}
cout << prefix;
return 0;
}알고리즘:
가장 긴 공통 접두사 찾기:
문자열들의 가장 긴 공통 접두사를 찾기 위해 두 문자열을 비교합니다.
두 문자열의 각 위치에서부터 순서대로 비교하면서, 다른 문자가 나올 때까지 비교합니다.
다른 문자가 나오면, 그 위치 이전까지가 공통 접두사입니다.
모든 문자열에 대해 공통 접두사 찾기:
처음에는 첫 번째 문자열을 가장 긴 공통 접두사로 설정합니다.
두 번째 문자열부터 마지막 문자열까지 차례대로 공통 접두사를 찾습니다.
각 문자열과 이전까지의 공통 접두사를 비교하여 더 짧은 길이의 접두사를 새로운 공통 접두사로 갱신합니다.
이렇게 모든 문자열에 대해 공통 접두사를 찾으면 가장 긴 공통 접두사가 나옵니다.
필요한 문법:
반복문(for 루프):
for 루프를 사용하여 문자열들을 반복하고, 각 문자열의 문자를 비교합니다.
문자열 비교 및 조작:
문자열을 비교할 때는 일반적으로 == 연산자를 사용합니다.
문자열을 자르거나 추출할 때는 substr() 함수를 사용합니다.
벡터(vector):
벡터는 동적 배열로, 크기가 동적으로 조정될 수 있습니다.
push_back() 함수를 사용하여 원소를 벡터에 추가할 수 있습니다.
문자열 길이 구하기:
문자열의 길이를 구할 때는 length() 함수를 사용합니다.
조건문(if 문):
조건문을 사용하여 문자열의 일부를 추출하거나 업데이트합니다.

#include <iostream>
#include <fstream>
#include <sstream>
#include <vector>
using namespace std;
vector<string> split_line(string line, char delimiter);
void insert_to_dict(pair<string,string> pair);
vector<pair<string,string>> dict;
int main() {
string line;
ifstream dict_file("shuffled_dict.txt");
while(getline(dict_file, line)) {
auto item = split_line(line, '\t');
auto p = make_pair(item[0], item[1]);
insert_to_dict(p);
}
dict_file.close();
for (auto item: dict)
cout << item.first << ": " << item.second << endl;
string word;
cin >> word;
auto it=dict.begin();
for (; it!=dict.end() && it->first < word; it++);
if (it->first == word) { // found
cout << "Found:" << endl;
cout << it->first << ": " << it->second << endl;
}
else if (it == dict.begin()){
cout << "Not found" << endl;
cout << "+ " << it->first << ": " << it->second << endl;
}
else if (it==dict.end()) {
cout << "Not found" << endl;
cout << "- " << (it-1)->first << ": " << (it-1)->second << endl;
}
else {
cout << "Not found" << endl;
auto it2 = it-1;
cout << "- " << it2->first << ": " << it2->second << endl;
cout << "+ " << it->first << ": " << it->second << endl;
}
cout << "Results of prefix search:" << endl;
it=dict.begin();
for (; it!=dict.end(); it++) {
if ((it->first).find(word) == 0) {
cout << it->first << ": " << it->second << endl;
}
}
return 0;
}
void insert_to_dict(pair<string,string> pair) {
auto it=dict.begin();
for (; it!=dict.end() && it->first < pair.first; it++);
it = dict.insert(it, pair);
}
vector<string> split_line(string line, char delimiter)
{
vector<string> tokens;
stringstream sstream(line);
string str;
while(getline(sstream, str, delimiter))
tokens.push_back(str);
return tokens;
}필요한 헤더 파일과 전역 변수:
- <iostream>: 표준 입출력을 위한 헤더 파일입니다.
- <fstream>: 파일 입출력을 위한 헤더 파일입니다.
- <sstream>: 문자열 스트림 처리를 위한 헤더 파일입니다.
- <vector>: 동적 배열인 벡터를 사용하기 위한 헤더 파일입니다.
- using namespace std;: 표준 네임스페이스를 사용합니다.
- vector<pair<string,string>> dict;: 사전을 저장할 벡터입니다. 각 항목은 (단어, 정의) 쌍의 형태로 저장됩니다.
함수들:
- split_line(string line, char delimiter): 문자열을 구분자(delimiter)를 기준으로 나누어 벡터에 저장하는 함수입니다.
- insert_to_dict(pair<string,string> pair): 사전에 새로운 항목을 삽입하는 함수입니다. 사전은 단어의 오름차순으로 정렬되어 있어야 합니다.
- main(): 프로그램의 진입점입니다.
- 먼저, 텍스트 파일("shuffled_dict.txt")에서 각 줄을 읽어들여 단어와 정의를 추출하고, 이를 사전에 삽입합니다.
- 사용자로부터 단어를 입력받고, 이를 사전에서 검색하여 결과를 출력합니다.
- 또한, 입력된 단어로 시작하는 모든 단어들과 그에 해당하는 정의를 출력합니다.
설명:
- while(getline(dict_file, line)): dict_file에서 한 줄씩 읽어들입니다.
- auto item = split_line(line, '\t');: 각 줄을 탭(\t)을 기준으로 나누어 item에 저장합니다. 이는 단어와 정의를 추출하는 과정입니다.
- auto p = make_pair(item[0], item[1]);: 추출된 단어와 정의를 쌍(pair)으로 묶어 p에 저장합니다.
- insert_to_dict(p);: 쌍(pair)을 사전에 삽입합니다.
- for (; it!=dict.end() && it->first < word; it++);: 입력된 단어가 사전에 있는지 검색합니다. 단어의 오름차순으로 정렬된 벡터를 사용하여 이진 검색(binary search)을 수행합니다.
- if (it->first == word) { ... }: 단어가 사전에 있는 경우를 처리합니다.
- else if (it == dict.begin()) { ... }: 단어가 사전에 없고, 사전의 첫 번째 단어보다 작은 경우를 처리합니다.
- else if (it==dict.end()) { ... }: 단어가 사전에 없고, 사전의 마지막 단어보다 큰 경우를 처리합니다.
- else { ... }: 단어가 사전에 없고, 사전에 삽입할 위치를 찾은 경우를 처리합니다.
- for (; it!=dict.end(); it++) { ... }: 입력된 단어로 시작하는 모든 단어들을 출력합니다.
- void insert_to_dict(pair<string,string> pair) { ... }: 사전에 항목을 삽입하는 함수입니다. 이 함수는 이진 검색(binary search)을 사용하여 삽입할 위치를 찾습니다.
- vector<string> split_line(string line, char delimiter) { ... }: 문자열을 구분자(delimiter)를 기준으로 나누어 벡터에 저장하는 함수입니다. 이는 단어와 정의를 추출하는 데 사용됩니다.
이러한 구조와 기능을 통해 이 코드는 텍스트 파일에서 데이터를 읽어들여 사전을 구축하고, 사용자로부터 입력받은 단어에 대해 검색하며, 입력된 단어로 시작하는 모든 단어들을 출력합니다.
'IT 프로그래밍 > 객체지향프로그래밍' 카테고리의 다른 글
| 객체지향프로그래밍 2과 그룹액티비티 총정리 (0) | 2024.04.21 |
|---|---|
| 객체지향프로그래밍 그룹 액티비티 1과 총정리 (0) | 2024.04.21 |
| 객체지향 프로그래밍 25번 , 26번, 28번, 29번, 30번, 31번, 32번, 33번 (0) | 2024.04.20 |
| 객체지향프로그래밍 16번, 17,번, 18번, 19번, 22번, 23번, 24번 (0) | 2024.04.20 |
| 객체지향 프로그래밍 13번 , 14번, 15번 (0) | 2024.04.20 |